// trabajo final integrador
Ciberataques asistidos por IA generativa
vs. la capacidad de respuesta de un SOC
Un centro de operaciones de seguridad modelado como un sistema de colas M/M/c, para medir cuándo el crecimiento de la amenaza supera la capacidad del equipo — y qué lo sostiene.
01 / EL PROBLEMA
Presentación del problema
El fenómeno
La IA generativa bajó drásticamente el costo de producir ataques: el phishing generado por IA pasó de menos del 5 % a 56 % de los ataques detectados en un mes hacia fines de 2025, y las vulnerabilidades publicadas por año casi se triplicaron entre 2019 y 2025. Del otro lado, un equipo de respuesta (SOC) tiene una capacidad de análisis finita: una cantidad fija de analistas que sólo pueden procesar cierto número de alertas por hora.
Me interesa porque es un problema de capacidad vs. demanda con consecuencias reales: cuando las alertas llegan más rápido de lo que se pueden analizar, el tiempo de detección se dispara y los incidentes críticos quedan sin atender. Es exactamente lo que describe la teoría de colas.
Objetivos
- Analizar cuantitativamente la evolución de vulnerabilidades e incidentes reportados en fuentes públicas, comparando el período pre y post IA generativa.
- Modelar y simular cómo el aumento en la tasa de llegada de amenazas afecta la capacidad de un equipo de respuesta para detectarlas y mitigarlas a tiempo.
PREGUNTA DE INVESTIGACIÓN
¿Cómo impacta el crecimiento de ataques asistidos por IA en la capacidad de respuesta de un equipo de ciberseguridad, y qué condiciones —cantidad de analistas, nivel de automatización— permiten sostener tiempos de respuesta aceptables?
02 / LOS DATOS
Datos recolectados y procesados
Vulnerabilidades publicadas por año (CVEs)
Fuente: NVD / CVE Details. Usadas como proxy objetivo del crecimiento de la amenaza.
| Año | CVEs | Var. interanual |
|---|---|---|
| 2019 | 17.305 | — |
| 2020 | 18.323 | +5,9 % |
| 2021 | 20.153 | +10,0 % |
| 2022 | 25.084 | +24,5 % |
| 2023 | 29.066 | +15,9 % |
| 2024 | 40.313 | +38,7 % |
| 2025 | 48.448 | +20,2 % |
| CAGR | +18,7 % anual (2019→2025) | |
Crecimiento de ataques asistidos por IA
- ×14 Phishing generado por IA: de <5 % a 56 % de los ataques detectados en un mes (fines de 2025). — Hoxhunt Phishing Trends Report 2026
- +72 % Ataques asistidos por IA desde 2024. — Total Assure, AI Cybersecurity Statistics 2025
- +58,2 % Phishing general en 2023 vs. 2022. — Zscaler ThreatLabz 2024 Phishing Report
Capacidad de un SOC real (calibración)
- 4.400+ alertas por día en un SOC promedio. — Vectra AI
- 16 d dwell time medio de detección (2023); objetivo <24 hs. — Mandiant M-Trends 2024
- 5 · 7′ ejemplo de dimensionamiento: 5 analistas, ~17 hs/día de triage, ~7 min por alerta. — Prophet Security
Fuentes citadas
- NVD / CVE Details — conteo de CVEs publicadas por año.
- Hoxhunt — Phishing Trends Report 2026.
- Total Assure — AI Cybersecurity Statistics 2025.
- Zscaler — ThreatLabz 2024 Phishing Report.
- Vectra AI — volumen de alertas de un SOC.
- Mandiant — M-Trends 2024 (dwell time).
- Prophet Security — ejemplo ilustrativo de dimensionamiento de un SOC.
03 / MODELO Y SIMULACIÓN
Descripción del modelo
¿Por qué una cola M/M/c?
Un SOC es un sistema de colas multiservidor: llegan alertas de forma
aleatoria, esperan si todos los analistas están ocupados, y son atendidas en
paralelo por c analistas.
| alertas | clientes que llegan |
| Poisson (λ) | llegadas aleatorias e independientes |
| c analistas | servidores en paralelo |
| triage (μ) | tiempo de servicio (exponencial) |
| cola FIFO | alertas pendientes |
Elegimos servicio exponencial (M/M/c) a propósito: tiene fórmula cerrada (Erlang-C), lo que permite validar la simulación contra la teoría. El simulador coincide con Erlang-C dentro de ~1–2 %.
Variables y fórmulas
μ = 1 / E[S] # tasa de servicio por analista
ρ = λ / (c·μ) # utilización (estable si ρ < 1)
a = λ / μ # carga ofrecida (erlangs)
C(c,a) # Erlang-C: P(una alerta espera)
Wq = ───────────── # espera media en cola
c·μ − λ
Lq = λ · Wq # alertas en cola (Ley de Little)
Calibración: E[S]=7 min → μ≈8,57/h, c=5,
λ₀≈30/h (720/día) para ρ=0,70. La amenaza crece con
λ(t)=λ₀·(1+r)t·fIA, con
r=18,7 % (CAGR de CVEs) y un factor de aceleración por IA.
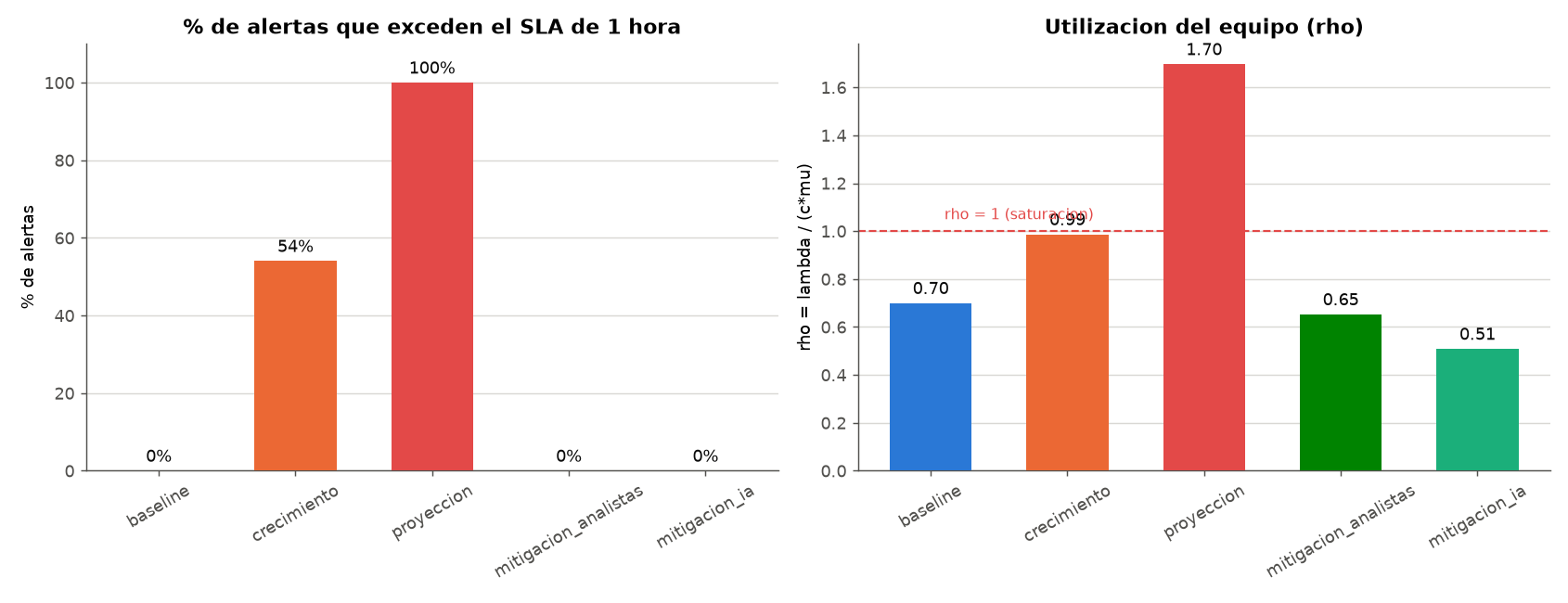
Panel de estado — utilización (ρ) por escenario
El hallazgo central de un vistazo: cada barra es la utilización del equipo; la línea marca la saturación (ρ = 1), donde la cola crece sin límite.
Resultados de la simulación
| Escenario | λ (alertas/día) | Analistas | ρ | Espera media | % excede SLA | Estado |
|---|---|---|---|---|---|---|
| Baseline | 720 | 5 | 0,70 | ~1,8 min | 0 % | OK |
| Crecimiento actual (+2 años) | 1.015 | 5 | 0,99 | ~84 min | 54 % | ADVERTENCIA |
| Proyección + IA | 1.745 | 5 | 1,70 | diverge | 100 % | SATURADO |
| Mitigación: +analistas | 1.745 | 13 | 0,65 | ~0,2 min | 0 % | OK |
| Mitigación: IA de triage (−70 % vol.) | 524 | 5 | 0,51 | ~0,4 min | 0 % | OK |
Supuestos y limitaciones
Explicitarlas es parte de la reflexión crítica: el modelo es coherente, no exhaustivo.
- Cola FIFO sin priorización por severidad (en un SOC real habría clases de alerta).
- Tiempo de servicio exponencial: simplifica la cola larga de casos complejos reales.
- Las CVEs son un proxy del crecimiento de amenazas, no una medida directa de ataques.
- Cerca de saturación (ρ≈0,99) la simulación a horizonte finito queda ~17 % por debajo de la teoría: efecto de alta varianza conocido, no un error del código.
04 / TRANSPARENCIA
Uso de IA y otras herramientas
Este trabajo se desarrolló con asistencia de herramientas de IA generativa. Abajo, en qué etapa se usó cada una, con espacio para la reflexión crítica (validación, correcciones y limitaciones) que completo en primera persona.
| Etapa del trabajo | Herramienta | Para qué |
|---|---|---|
| 1 · Definición del tema y objetivos | Claude.ai | Acotar el tema con preguntas guiadas antes de desarrollar. |
| 2 · Recolección y análisis de datos | Claude.ai | Búsqueda y curación de fuentes públicas con cifras citadas. |
| 3 · Implementación del modelo | Claude Code | Modelo M/M/c en SimPy, 5 escenarios, validación Erlang-C. |
| 4 · Desarrollo del portafolio | Claude Code | Esta página web de entrega. |
-
Definición del tema y objetivos
Prompt (resumido): pedí acotar un tema de Modelos y Simulación relacionado con ciberseguridad e IA, mediante preguntas guiadas, antes de desarrollar nada.
[TODO: completar reflexión] — ¿La IA propuso un tema realista y acotable? ¿Qué ajusté del enfoque? ¿Qué decidí yo?
-
Recolección y análisis de datos reales
Prompt (resumido): búsqueda y curación de datos públicos (NVD, Hoxhunt, Zscaler, Mandiant, Vectra, Prophet Security), con cifra y fuente citada para cada una.
[TODO: completar reflexión] — ¿Verifiqué las cifras contra las fuentes originales? ¿Alguna no coincidía o estaba desactualizada? ¿Qué descarté?
-
Implementación del modelo
Prompt (resumido): estructura del proyecto, modelo M/M/c, datos de calibración y 5 escenarios; se pidió proponer el modelo y las fórmulas antes de escribir código, para revisarlo primero. El simulador se validó contra Erlang-C (~1–2 %).
[TODO: completar reflexión] — ¿La validación contra Erlang-C me dio confianza en el código? ¿Qué supuestos discutí o corregí antes de implementar?
-
Desarrollo del portafolio
Prompt (resumido): construir esta página web de entrega (HTML/CSS/JS plano, sin frameworks), cubriendo el checklist de la cátedra, con diseño tipo panel de SOC.
[TODO: completar reflexión] — ¿Revisé que la página no distorsione ningún dato del trabajo? ¿Qué contenido ajusté a mano?
05 / EVIDENCIA
Capturas, gráficos y archivos
Gráficos generados por la simulación (src/visualize.py → outputs/).
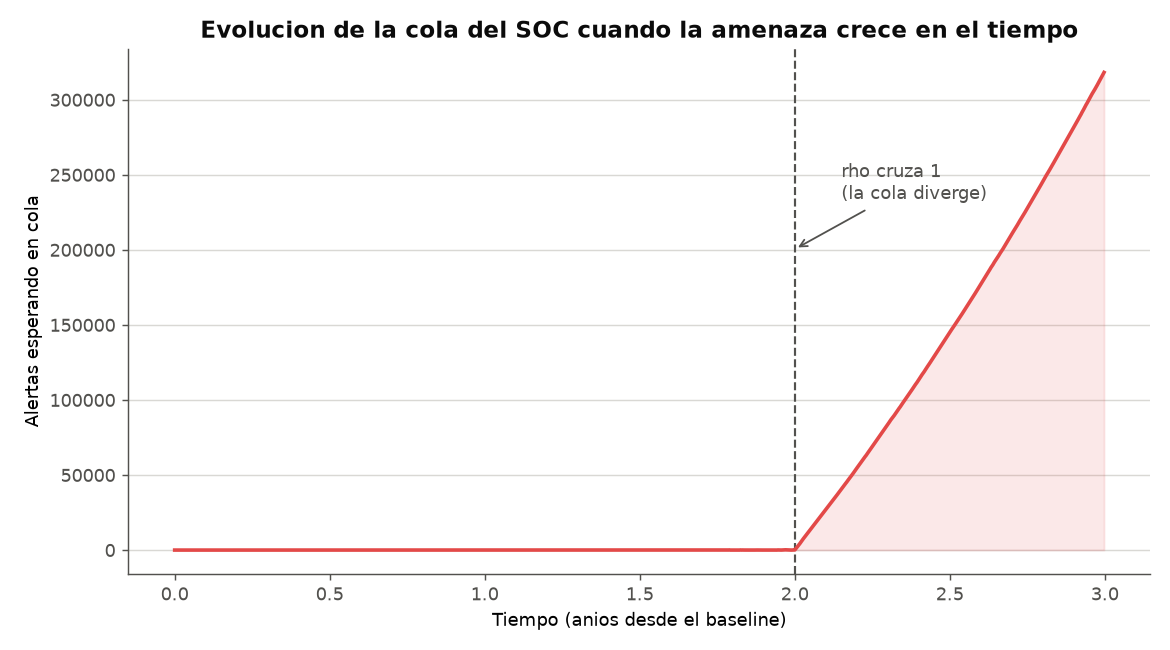
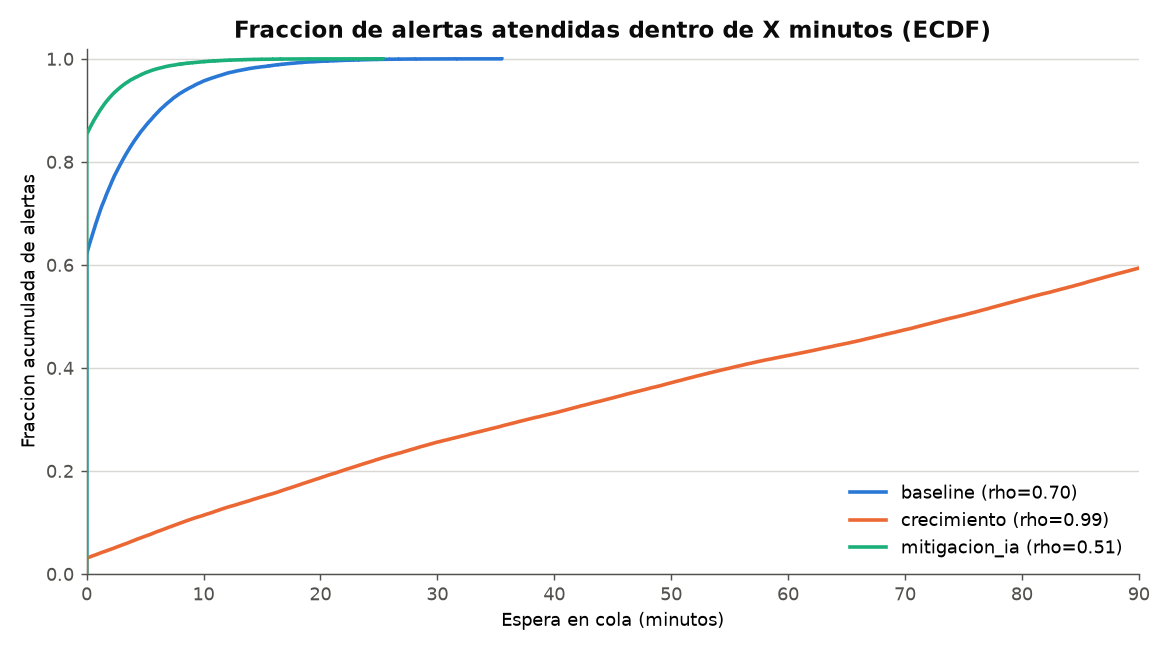
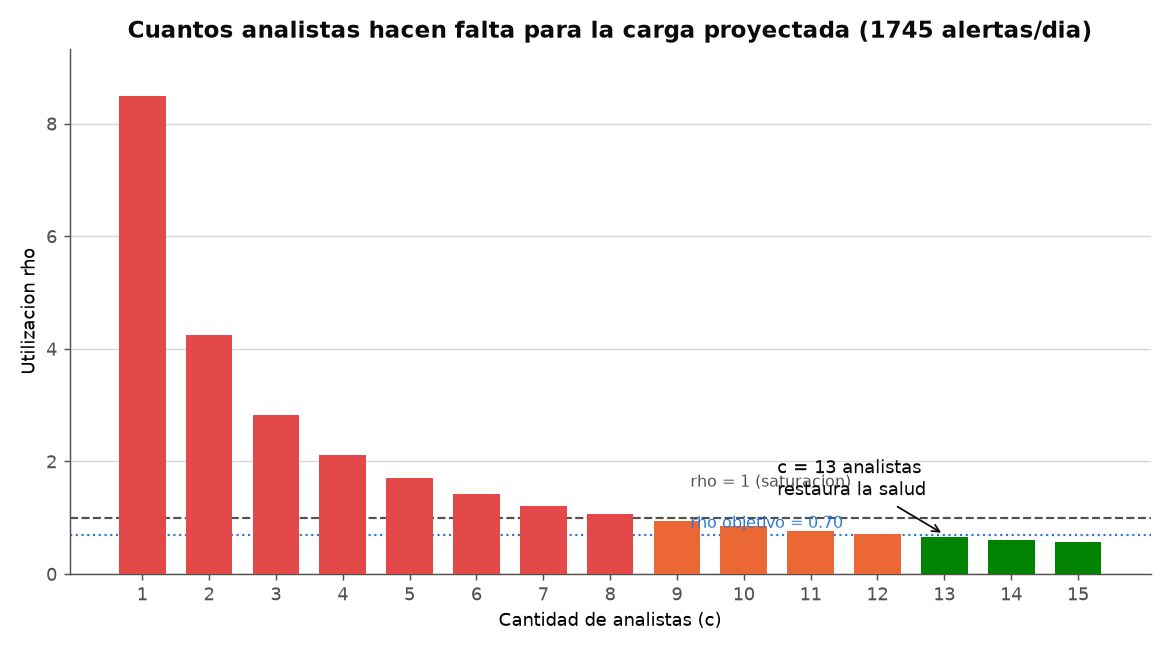
Evidencia de validación — simulación vs. teoría
Salida real de python src/model.py: el simulador coincide con la
fórmula Erlang-C con un error <2 %, lo que da confianza en que el código es correcto.
$ python src/model.py === Validacion simulacion vs. Erlang-C (baseline) === metrica teorico simulado error_% Utilizacion (rho) 0.700000 0.699030 -0.14 Espera media Wq (h) 0.029387 0.029041 -1.18 Alertas en cola Lq 0.881623 0.866333 -1.73
Código y datos completos del proyecto: modelo (src/model.py),
escenarios (src/scenarios.py), datos de calibración (data/) y
documentación formal (docs/modelo.md).
06 / INFORME FINAL
Conclusiones y reflexión crítica
Un crecimiento anual moderado (~18,7 %, la tasa real observada en CVEs) consume el margen de un SOC de 5 analistas en ~2 años. El factor de aceleración de la IA lleva al sistema al colapso (ρ>1).
De las dos mitigaciones simuladas, escalar el equipo humano funciona pero es costoso y lento de ejecutar en la realidad (pasar de 5 a 13 analistas). Automatizar el triage con IA da mejor resultado con menor costo operativo: los mismos 5 analistas vuelven a una utilización cómoda. La IA aparece, a la vez, como parte del problema y como la palanca más eficiente de la solución.
Sobre el uso de tecnología y datos: la conclusión es cualitativa y robusta pese a las limitaciones del modelo. Los datos públicos permiten calibrar la tasa de crecimiento con solidez, aunque el nivel absoluto de alertas dependa de supuestos de la industria. La validación del simulador contra la fórmula Erlang-C fue clave para confiar en los resultados y no en una "caja negra".
REFLEXIÓN PERSONAL
[TODO: escribí acá tu reflexión en primera persona — qué aprendiste, qué te sorprendió de los resultados, qué harías distinto, y tu postura sobre el uso de IA en ciberseguridad y en tu propio proceso de trabajo.]